Overview + Motivation
Why egocentric pointing remains hard for current MLLMs
EgoPoint-Bench evaluates multimodal pointing reasoning in egocentric vision. It targets a core failure mode we call referential hallucination: models answer about nearby or visually salient objects instead of the true referent indicated by a first-person pointing gesture.
This failure is especially common in egocentric scenes, where hand proximity, clutter, and partial visibility make naive visual grounding unreliable. EgoPoint-Bench is built to expose that gap directly, rather than treating pointing as generic visual QA.
The benchmark combines a scalable simulation pipeline with real-world capture, covering basic perception, function and state, spatial context, OCR, and adversarial resilience.

Pipeline
From Point-Sim supervision to real-world evaluation
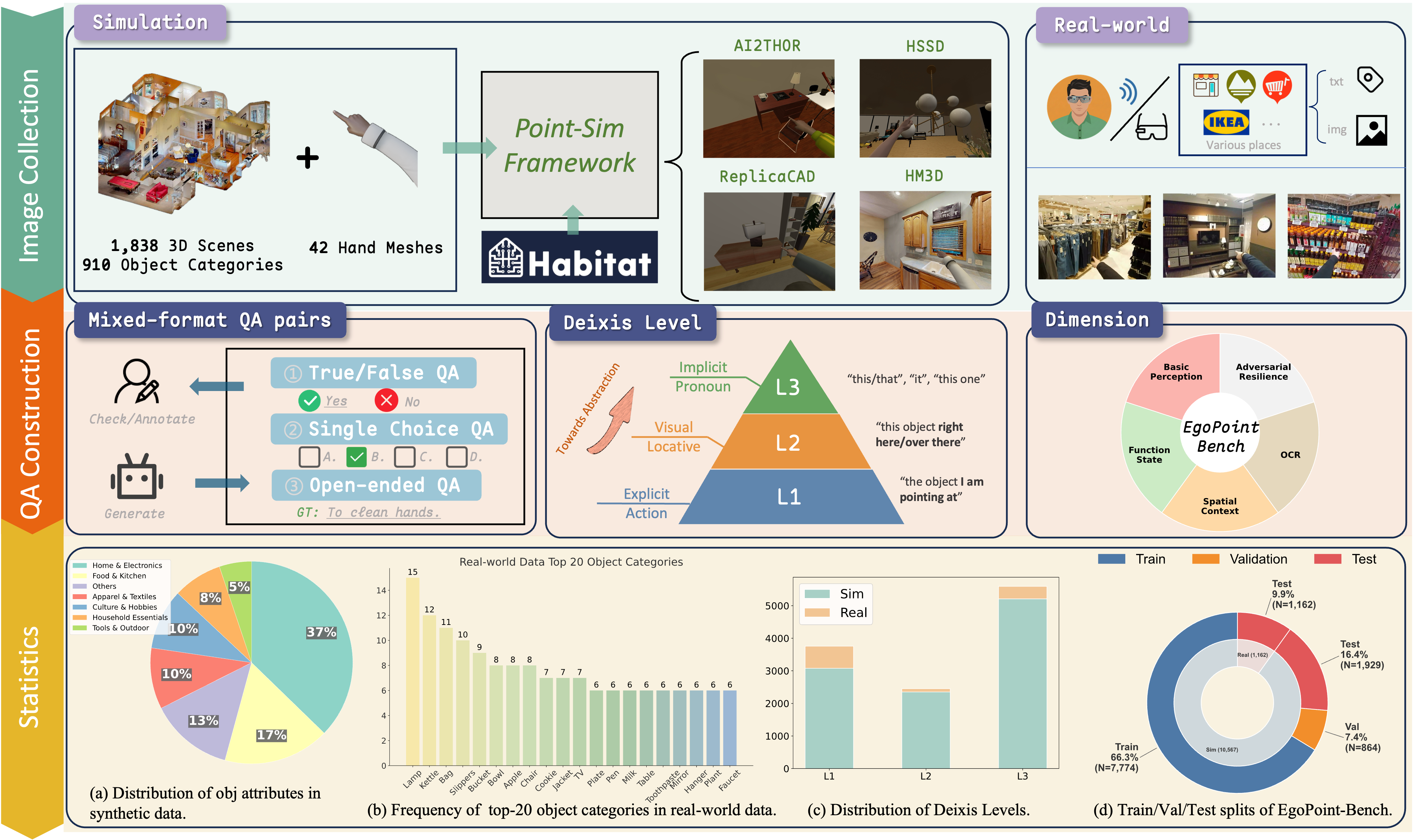
Highlights
What the benchmark covers
Capability Taxonomy
Five evaluation dimensions: Basic Perception, Function & State, Spatial Context, OCR, and Adversarial Resilience.
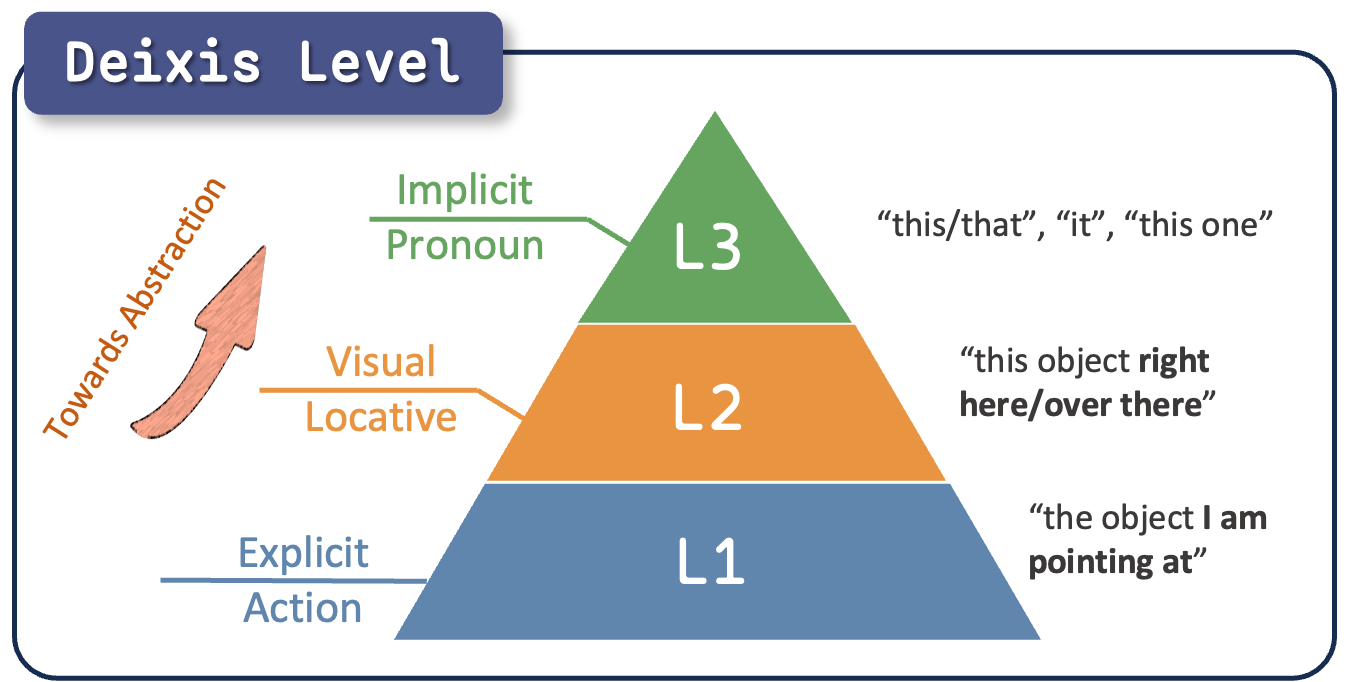
Hierarchical Deixis
Three deixis levels capture the ambiguity spectrum from explicit reference to fully implicit pronouns.
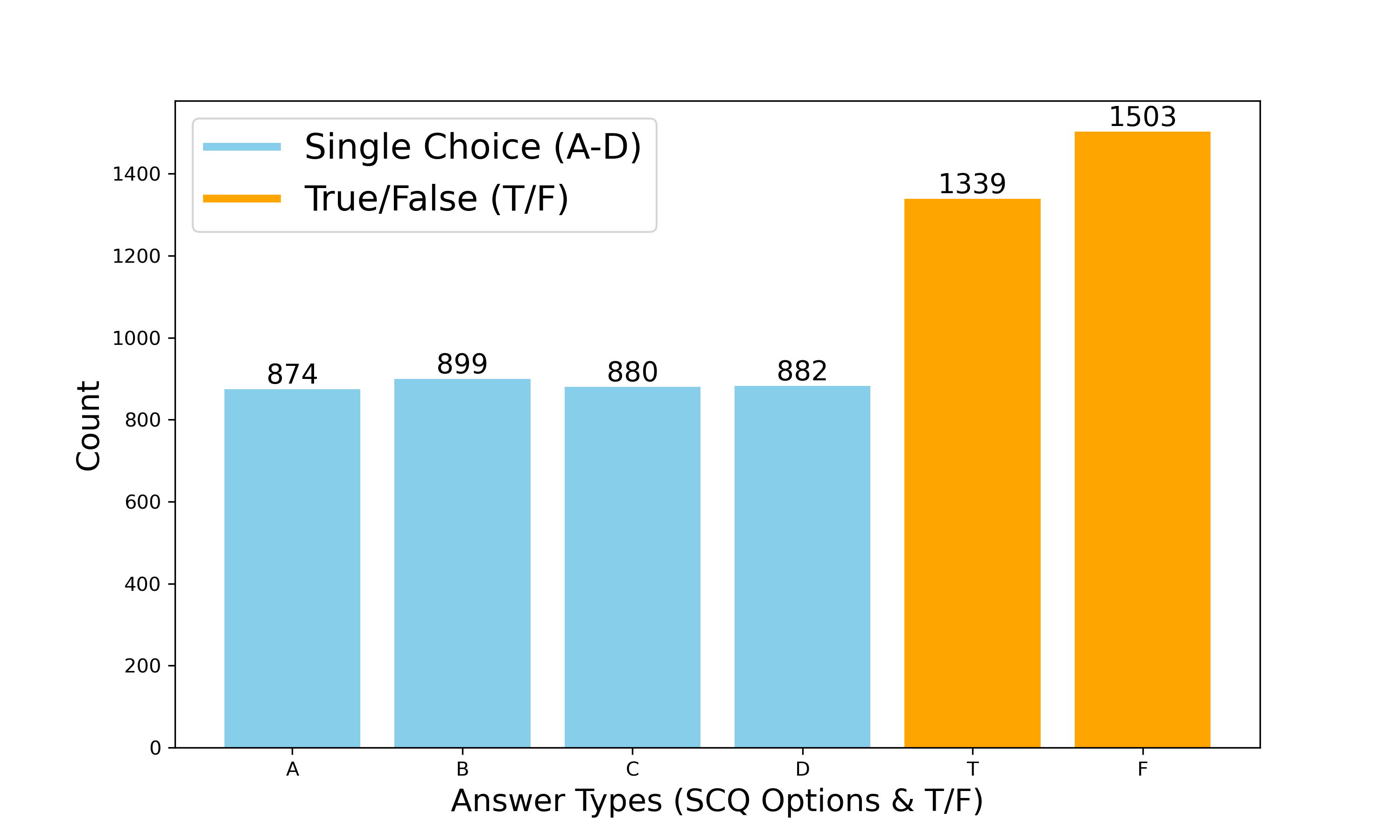
Mixed Question Format
Multiple-choice, true/false, and open-ended questions balance objective benchmarking with realistic user intent.
Sim-to-Real Focus
The dataset is constructed to support training and transfer, not just static leaderboard evaluation.
Examples
Mini dataset preview
Real-world subset





Simulation subset




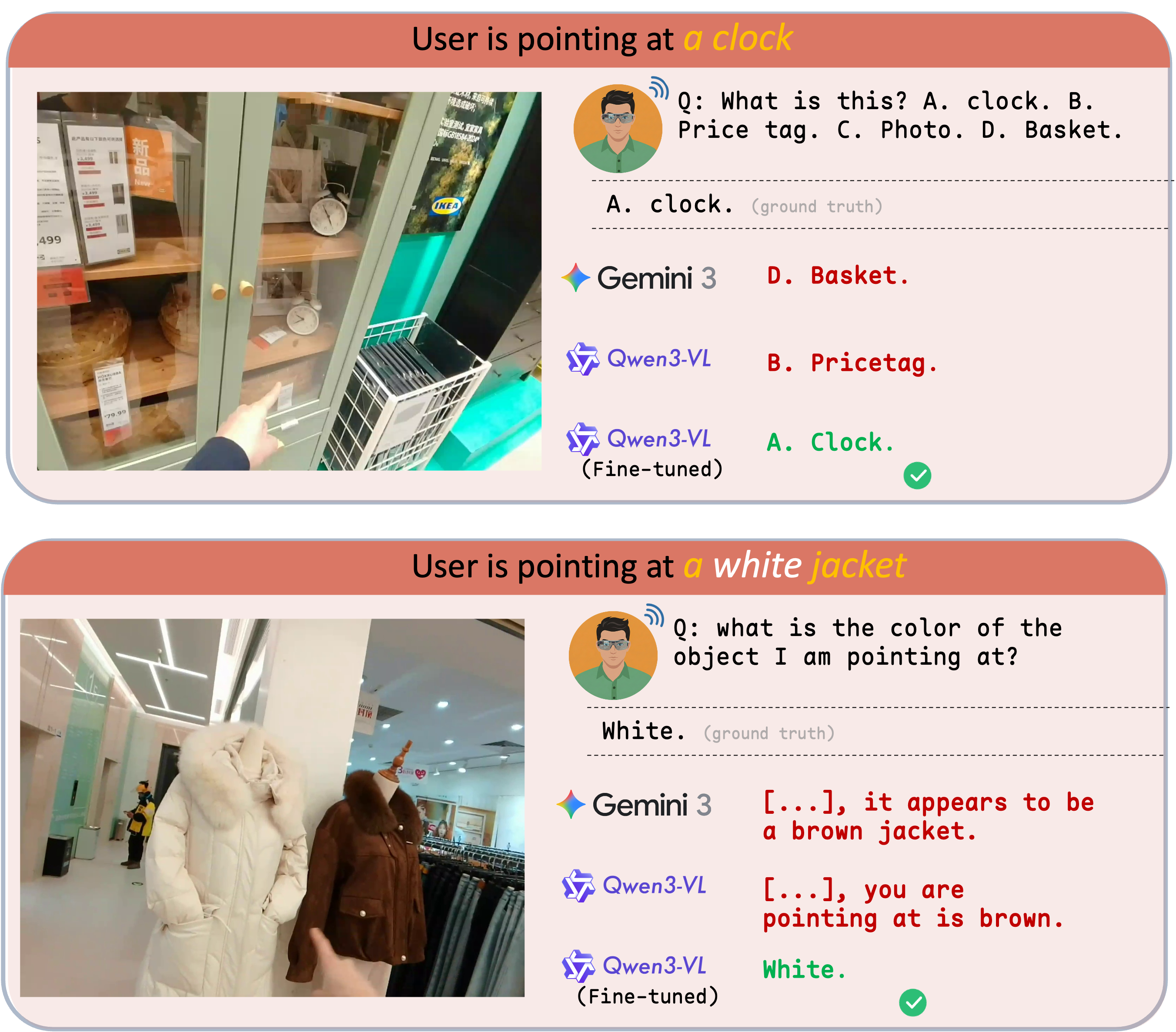
Failure Mode
Referential hallucination is visually plausible but wrong
Beyond the teaser examples, the error pattern is consistent: strong multimodal models often confuse the intended referent with objects close to the hand, along cluttered shelves, or in visually dominant regions.
EgoPoint-Bench is designed to measure this failure directly and to support methods that improve grounded gesture reasoning under real egocentric ambiguity.
Main Results
Simulation tuning improves egocentric deictic reasoning and transfers to real-world scenes
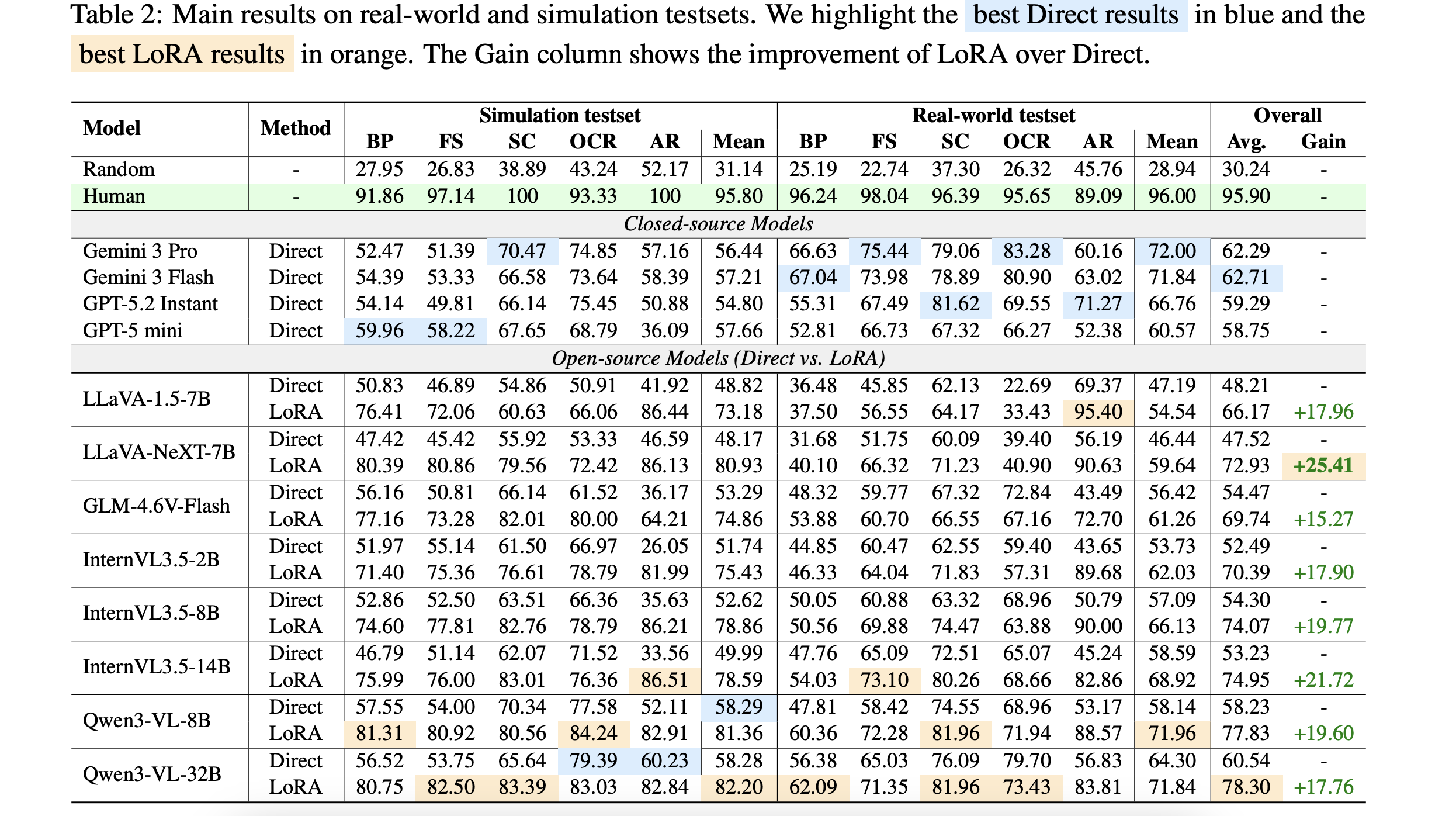
Off-the-shelf Limits
Directly prompted VLMs remain weak on fine-grained egocentric deictic understanding, especially under ambiguity and distractors.
Large Gains from Simulation
Simulation-based LoRA tuning delivers consistent and often substantial gains over direct inference across most open-source backbones.
Effective Sim-to-Real Transfer
Performance improvements learned in simulation largely carry over to real-world data, indicating strong practical generalization.
Citation
BibTeX
@misc{li2026mllmsunderstandpointingbenchmarking,
title={Do MLLMs Understand Pointing? Benchmarking and Enhancing Referential Reasoning in Egocentric Vision},
author={Chentao Li and Zirui Gao and Mingze Gao and Yinglian Ren and Jianjiang Feng and Jie Zhou},
year={2026},
eprint={2604.21461},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.21461},
}